What is Agentic Search?

Agentic search aims to mimic the human process of research for information retrieval.
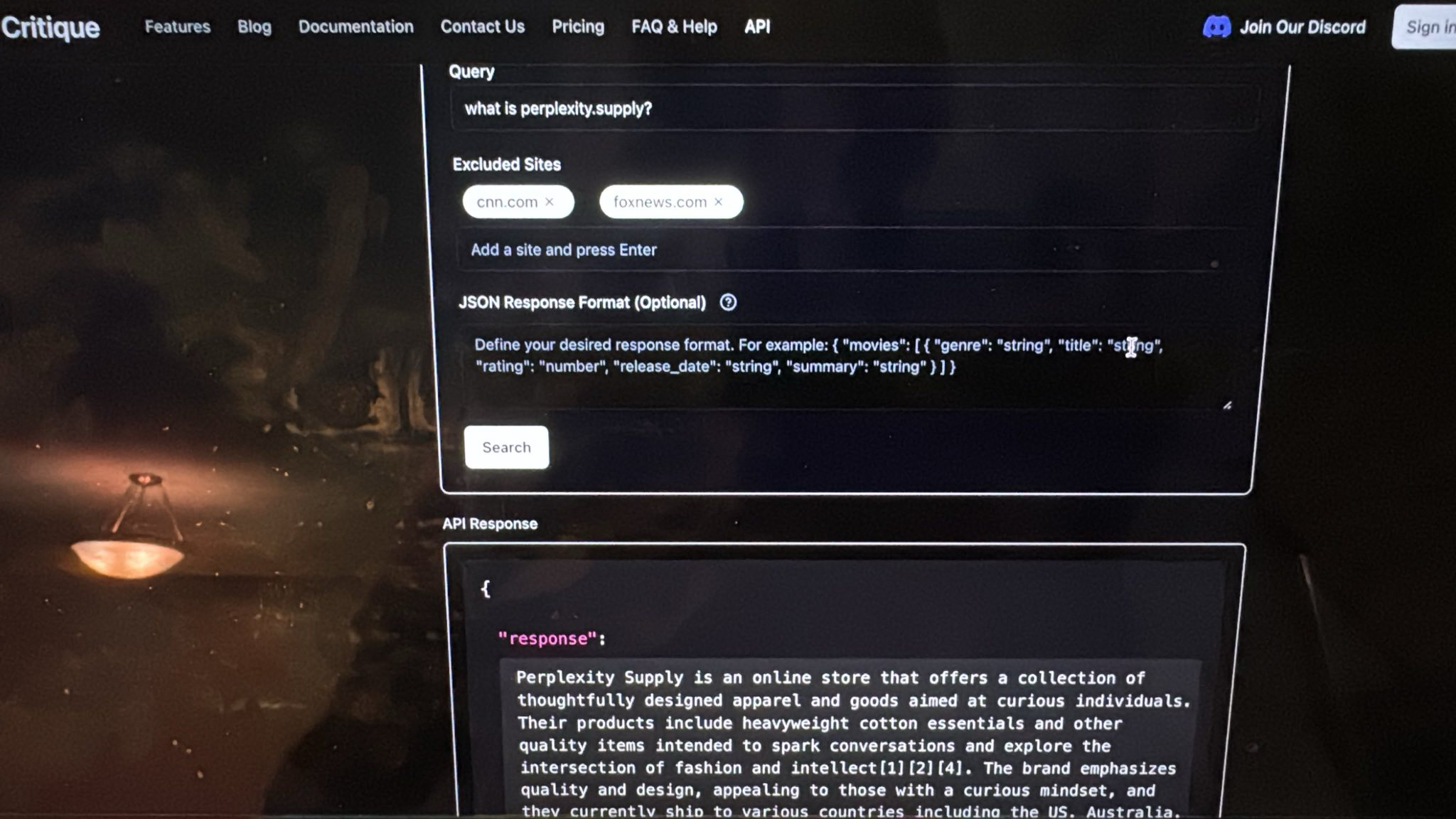
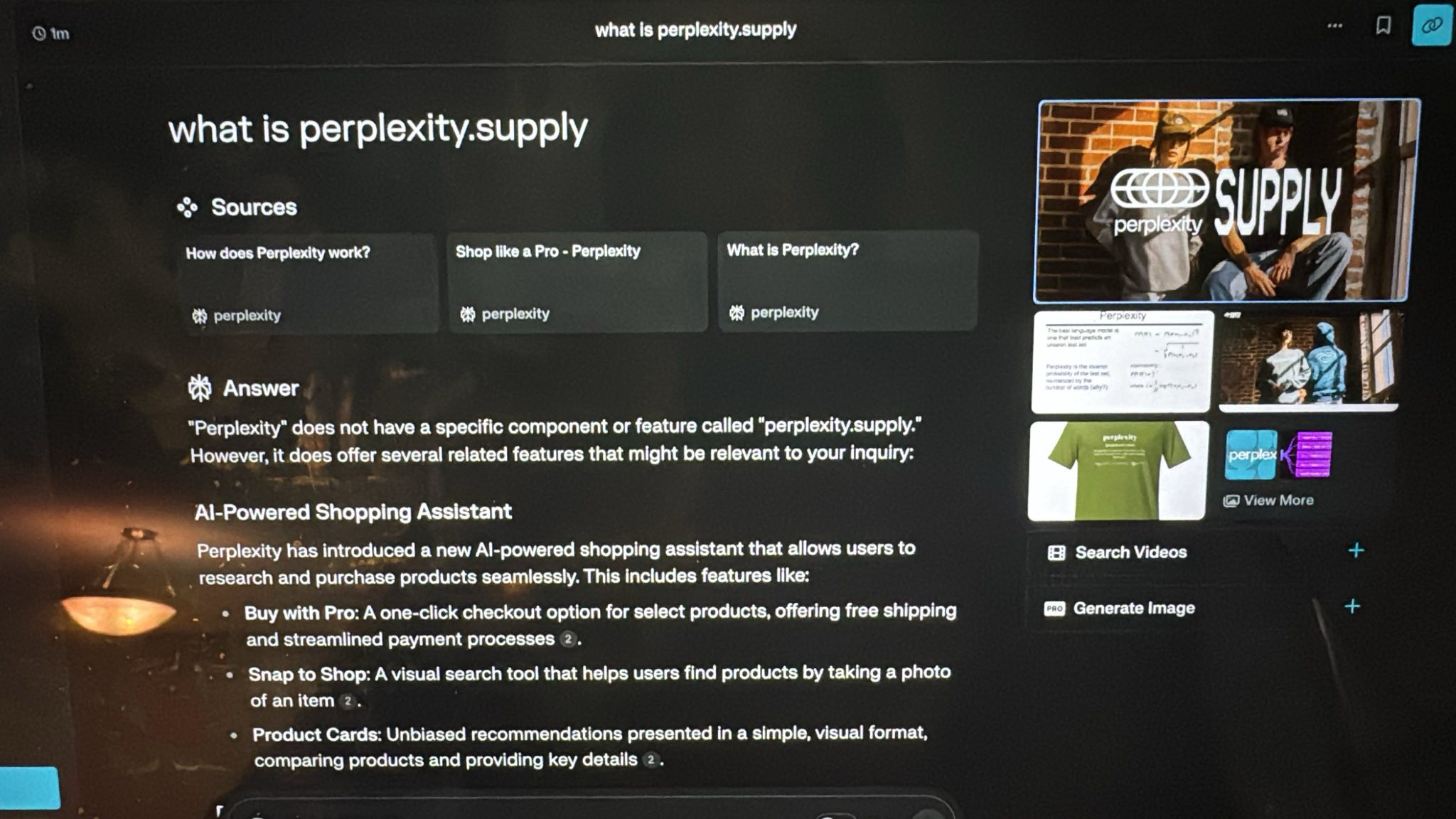
Perplexity had just released their own merch store that week: perplexity.supply. Here is the exact same query "what is perplexity.supply?" taken on 12/6/24 and their responses on Critique and Perplexity respectively. There's more examples at the bottom of the page.
Understanding Agentic Search
Currently, the leading model providers like Perplexity , OpenAI, and Claude have started offering a version of grounded search based response (where they offer citations and sources in the response). They all employ some combination of retrieval-augmented generation (RAG) to produce said grounded outputs. The implementation details differ slightly, but it involves using vector search on indexed web pages, followed by BM25 and other reranking methods to determine what content should be included in the context along with your query Source enabling needle in the haystack type retrieval for your response. We break down the limitations of this approach further below, but fundamentally it's just not how humans perform research in the involved sense of the term (not just search/lookup which is practically a solved problem even prior to the advent of LLMs). Agentic search was developed with the aim to mimic the human process of inquiry for information retrieval, as we'll explain later.
The Canonical Approach: Retrieval-Augmented Generation (RAG)
RAG and its variations are the backbone of most grounded LLM search systems, forming the basis of responses from Perplexity, OpenAI, Claude, and others. The process generally works as follows:
- Search and retrieval: Queries are sent to a search engine or a vector database to retrieve a set of relevant documents. Ranking algorithms like BM25 are used to sort these results.
- Chunking: Large documents are split into smaller chunks, either semantically or heuristically.
- Integration into context: Relevant chunks are injected into the input context of the LLM.
- Response generation: The LLM synthesizes a response using the retrieved information.
While effective, this "RAG plus" method has limitations, such as relying on pre-indexed data, that may not have crawled in time (this is not admittedly not as big a problem, though we do show a pretty ironic example in the images above). But more importantly, it offers only shallow exploration of sources, when was the last time a single page or collections of page from an initial search contained enough information to answer a deep research question you had?
What's Agentic Search?
Agentic search builds on RAG while addressing its constraints by emulating how humans conduct in-depth research: replicating the recursive, exploratory nature of manual web page exploration. It employs graph-based exploration, where each node in the system's search graph represents an agent tasked with investigating specific aspects of the query. These agents are embodied with all the aforementioned RAG techniques as tool calls that can be invoked at the model's discretion. So the important thing to note is all the previously discussed methodology can still be invoked, when it decides it's appropriate, by the LLM. It has access to function calls that allow it to search the web, rank pages, chunk documents, and identify the most relevant pieces of information. When a retrieved document contains links, the agent can invoke a search web query to follow those links to explore additional sources, mirroring the way humans click through related links to gather context and further understanding. When information from existing sources raises further questions, the graph is capable of recursively calling itself to answer new questions.
Agents make decisions dynamically, determining in real time how to handle retrieved content—whether to chunk it, rank it, or perform additional related searches. They prioritize relevance and refine their approach based on intermediate findings. Unlike RAG, which relies on pre-indexed data, agentic search performs live queries, ensuring that responses are based on the most up-to-date information available. Information gathered across multiple layers of exploration is then synthesized into a coherent, comprehensive response, making it especially valuable for complex queries requiring nuanced understanding.
Example of Agentic Search in Action
Consider the query: "What is Perplexity Supply?" When this question was posed shortly after Perplexity launched their store, traditional RAG-based systems, including Perplexity's own engine, failed to identify the store because it hadn't yet been indexed in their vector database.
Agentic search, by contrast, succeeded by performing a live search, following links, and recursively exploring related pages. This approach allowed it to uncover the new information in real time and synthesize a response that was both accurate and detailed.
Accuracy vs Speed
The primary advantage of agentic search lies in its depth and robustness. By replicating the human research process, it:
- Provides more comprehensive and accurate answers.
- Avoids reliance on potentially outdated pre-indexed data.
- Adapts dynamically to the nuances of each query.
However, this comes with a trade-off: speed. Recursive exploration and dynamic decision-making require more time and computational resources compared to the faster, more lightweight RAG plus techniques. For users and applications where depth and reliability are critical, though, the benefits far outweigh the cost. Ultimately, the grounded search that conventional vector search and ranking is capable of is quite potent for a lot of use cases, but the fact that to opt for that method is an option available to this agentic search engine means it's performance is lower bounded by RAG, and only improved for complex research with this agentic flow.
Examples of Critique's Agentic Search vs other LLM search providers :
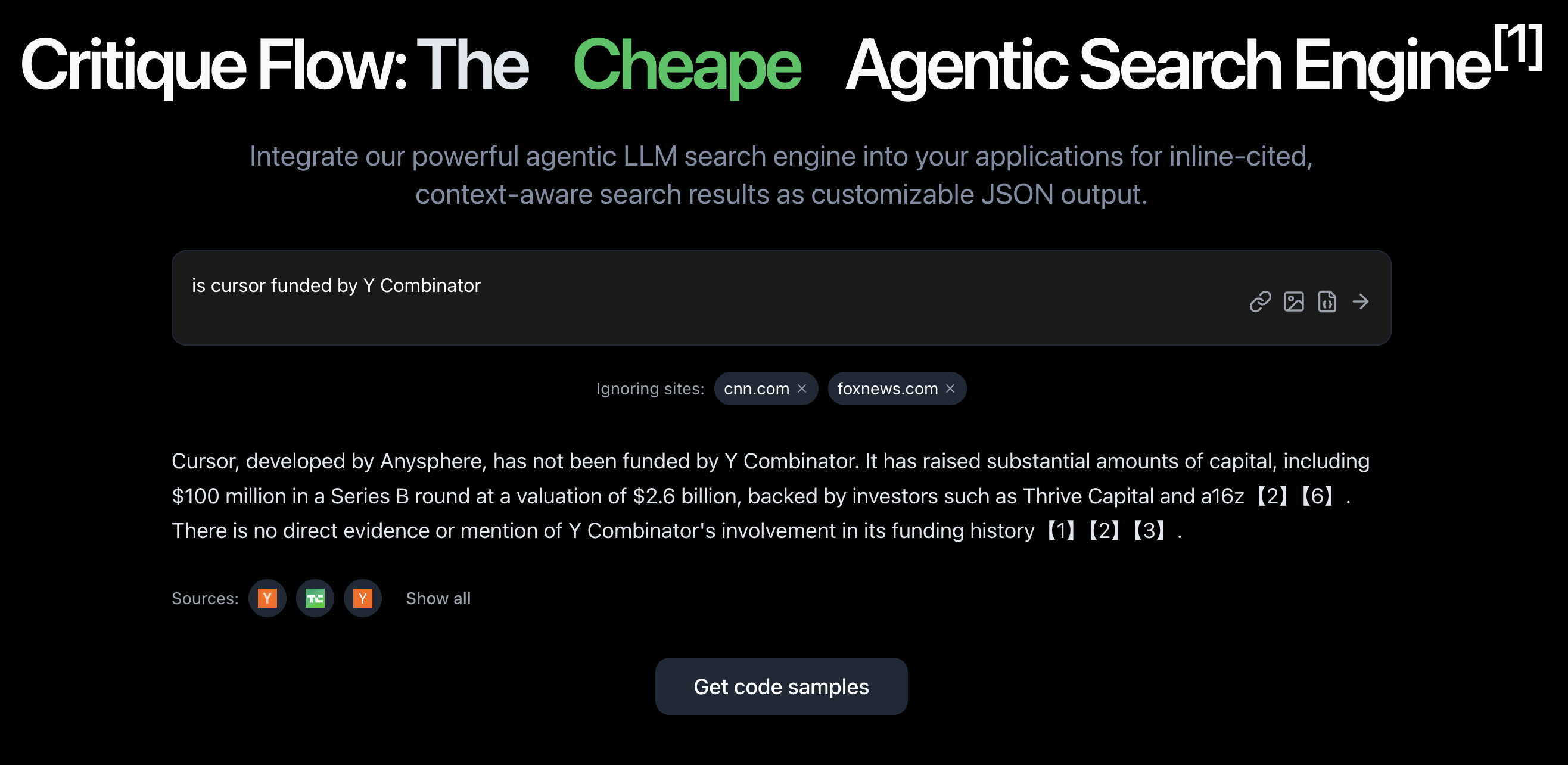
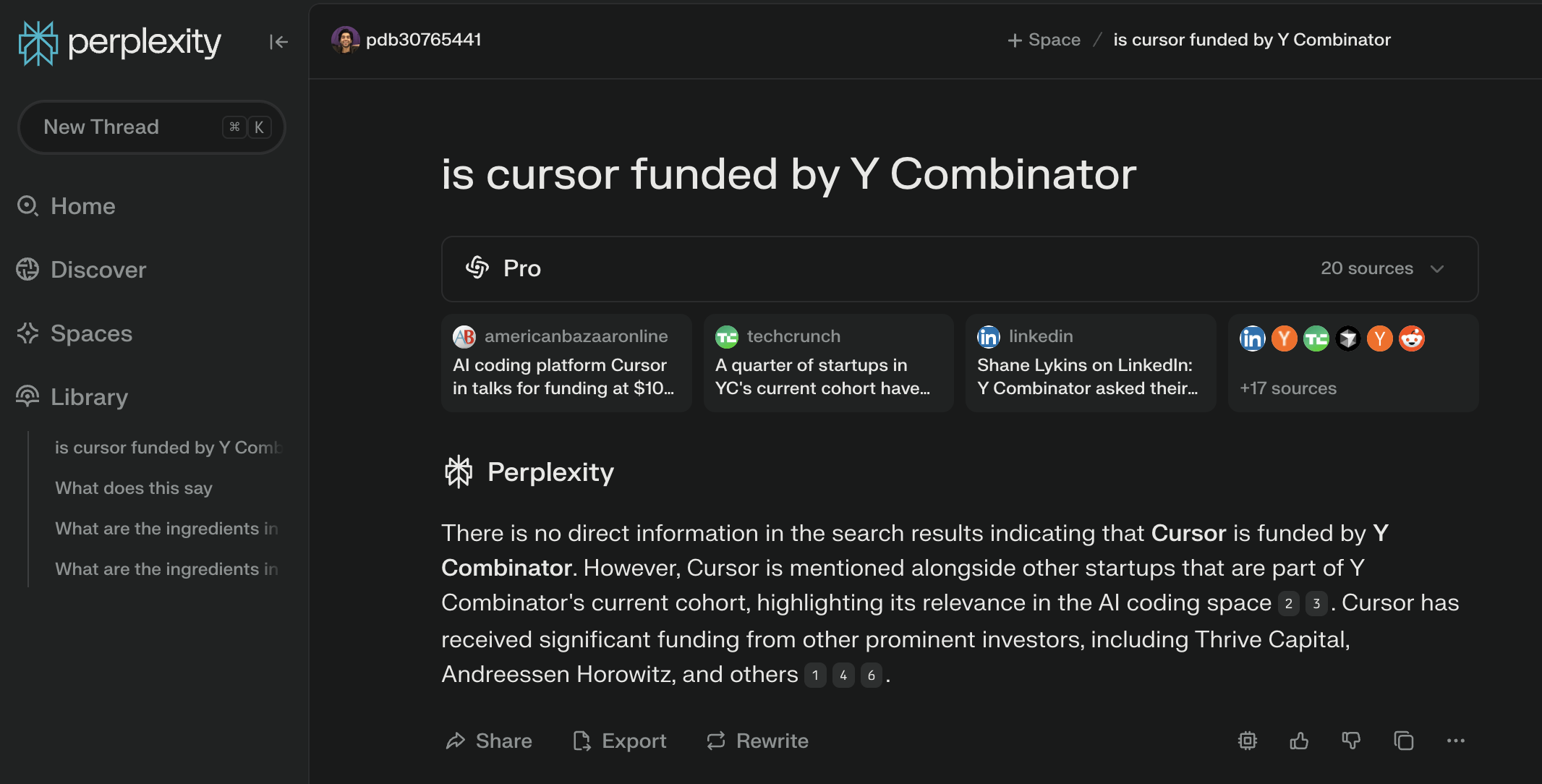
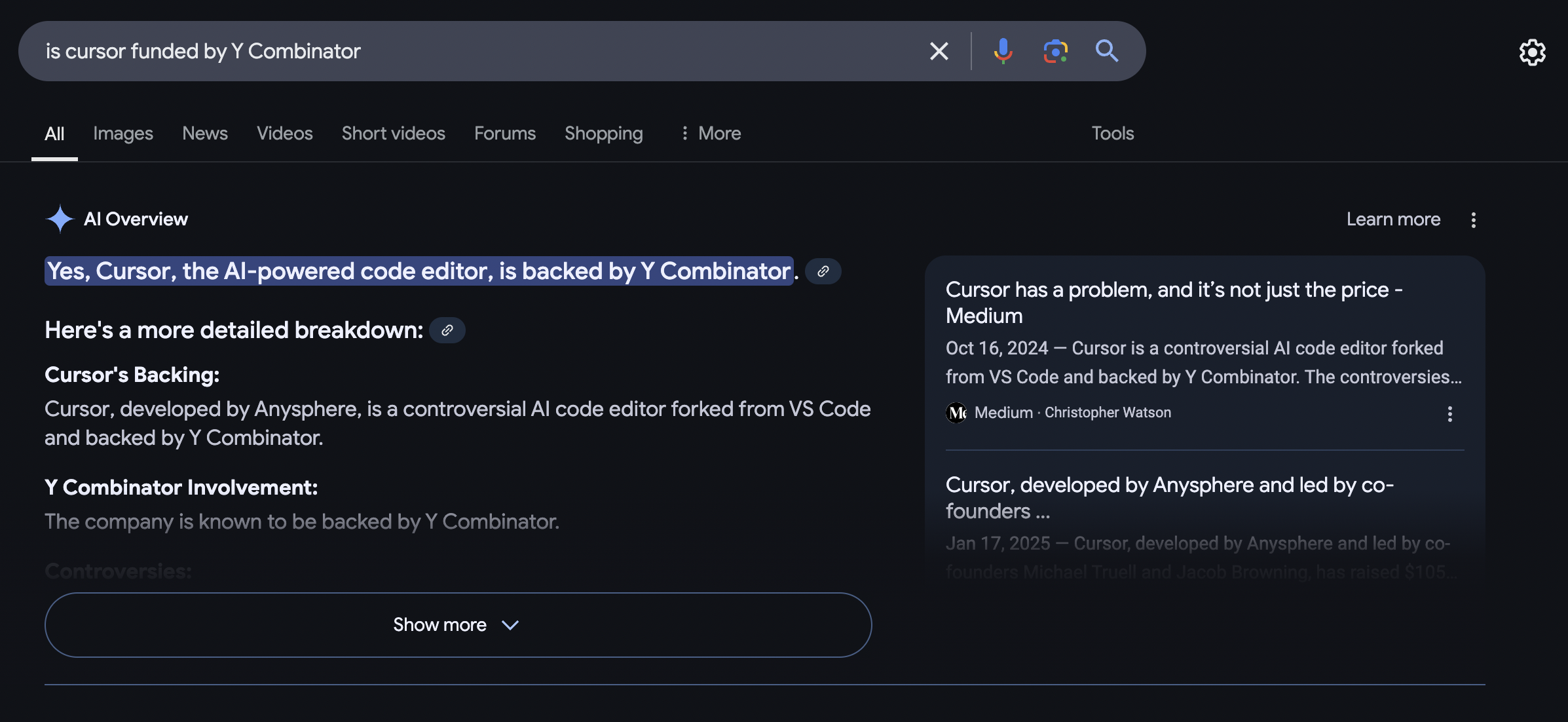
03/12/25: A quick search on if Cursor is funded by Y Combinator or not on Google, Perplexity, and Critique. Our agentic search engine is the only one that correctly identifies that it's not and that Cursor is a product of the company Anysphere.
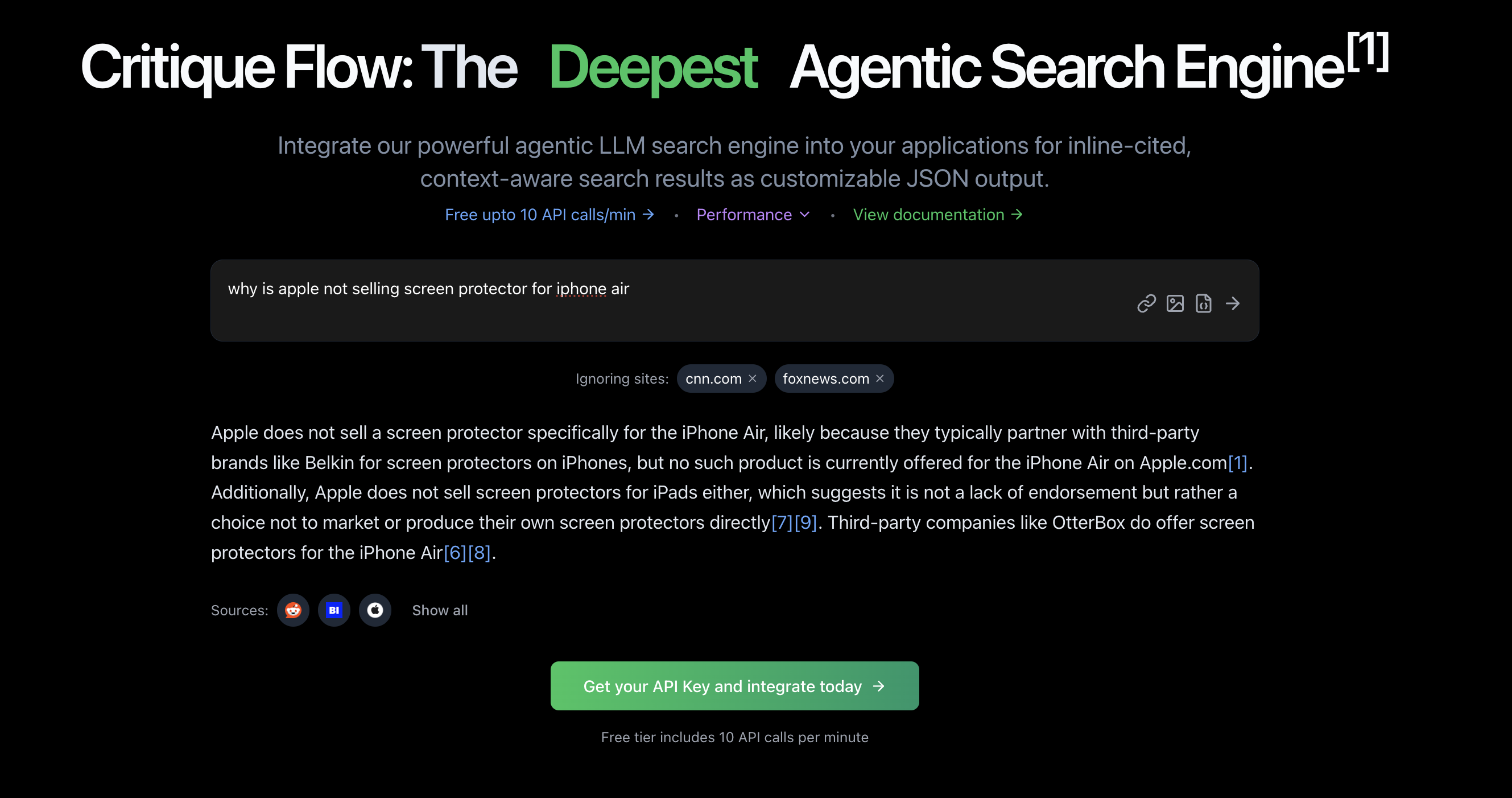
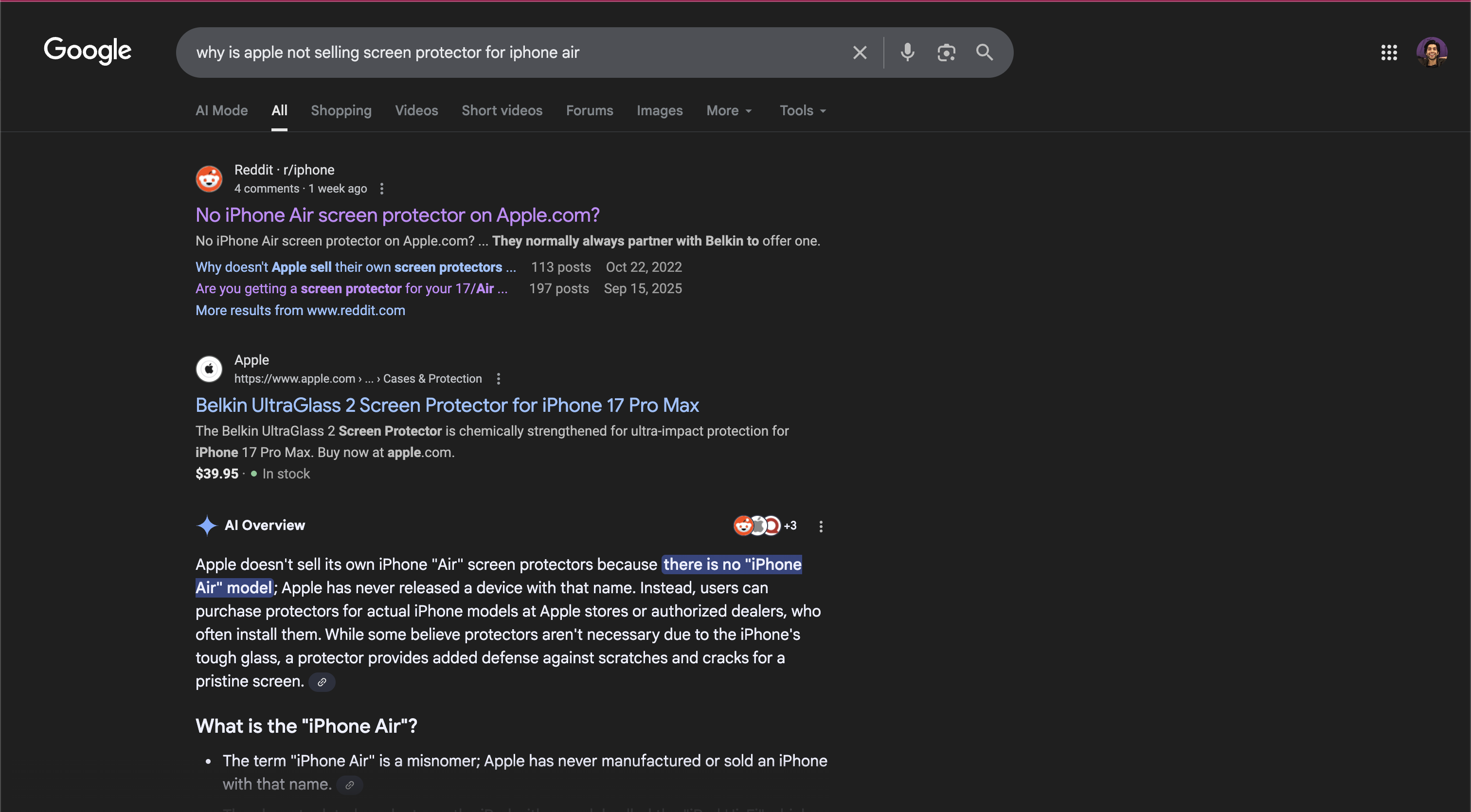
09/27/25: Searching for information on iPhone Air just after it's release, google claims there is no iPhone Air